问题描述
新站上线后,百度一直未收录。使用百度站长平台的“抓取诊断”工具进行测试时,发现抓取失败,并提示“socket读写错误”。
问题排查与原因分析
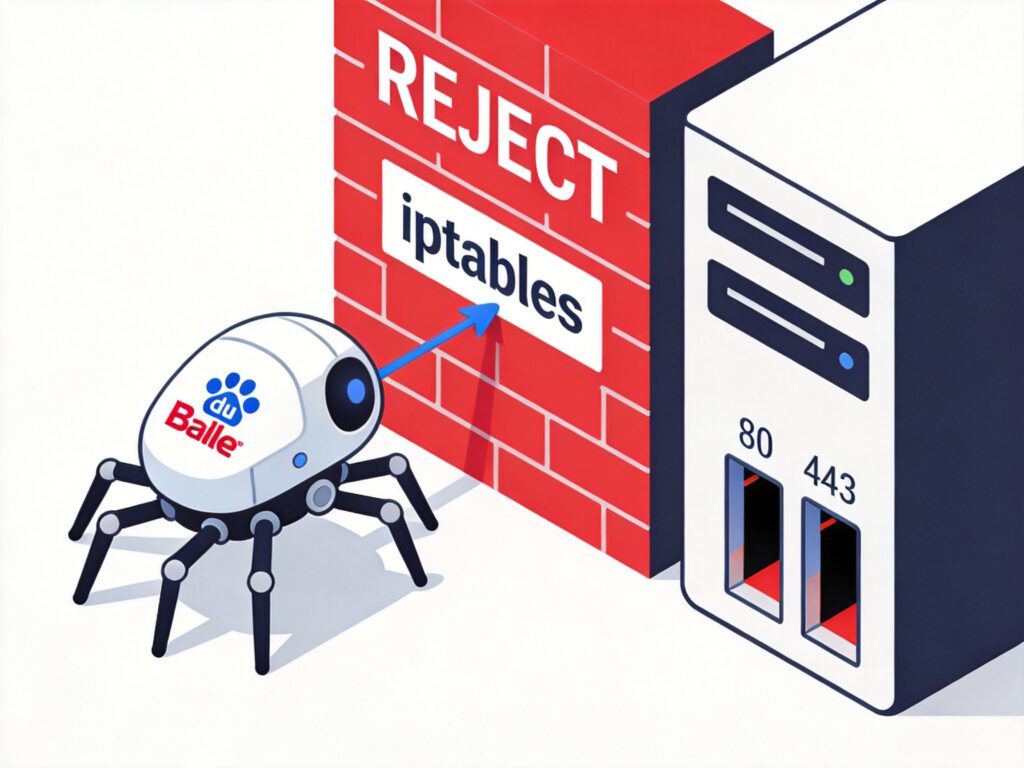
根据网络上的信息,此类错误通常与服务器的防火墙配置有关,特别是 iptables 规则。
检查服务器 iptables 规则后,发现问题源于一条通用的“拒绝所有”规则。许多管理员习惯在 iptables 规则链末尾添加以下命令,以禁止所有未明确允许的访问:
iptables -A INPUT -j REJECT
iptables -A FORWARD -j REJECT正是这条规则导致了百度蜘蛛(Baiduspider)在尝试抓取时,连接被服务器主动拒绝,从而触发了“socket读写错误”。
解决方案
删除或修改上述导致问题的 iptables 规则即可。具体删除方法可参考相关教程(例如:如何查看和删除特定 iptables 规则)。
移除该规则后,重新在百度站长平台进行抓取诊断,结果显示成功。
深入探讨与最佳实践
为什么以前网站没问题?
有用户反馈,旧网站同样配置了此规则却未出现问题。一个可能的差异是新站启用了 HTTPS/SSL。百度蜘蛛抓取 HTTPS 站点时,其网络行为可能与 HTTP 抓取存在细微差别,更容易触发某些严格的防火墙规则。
安全与便利的权衡
完全删除“拒绝所有”规则(-j REJECT)会降低服务器的默认安全级别,这并非最佳实践。更推荐的做法是:
- 为百度蜘蛛设置允许规则:根据百度官方公布的蜘蛛 IP 段,在 iptables 的 INPUT 链开头添加允许规则。
- 精细化控制:明确允许 80(HTTP)和 443(HTTPS)端口的入站连接,然后再设置默认的拒绝策略。
示例安全规则框架:
# 允许已建立的连接和回环接口
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -i lo -j ACCEPT
# 允许 HTTP 和 HTTPS 端口(根据实际情况调整)
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
iptables -A INPUT -p tcp --dport 443 -j ACCEPT
# 允许百度蜘蛛IP段(此处为示例,需替换为最新IP段)
# iptables -A INPUT -s 180.76.0.0/16 -j ACCEPT
# 设置默认策略为拒绝
iptables -P INPUT DROP
# 注意:使用-P DROP 而非 -A INPUT -j REJECT,后者在链末尾显式拒绝并返回拒绝包。注意:直接设置
iptables -P INPUT DROP作为默认策略,与在链末尾添加iptables -A INPUT -j REJECT效果类似,但后者会向请求方返回一个拒绝数据包,而前者是直接丢弃。对于百度蜘蛛而言,明确拒绝(REJECT)可能比静默丢弃(DROP)更容易被识别为网络问题。
总结
百度站长工具提示“socket读写错误”,很大程度上是由于服务器防火墙(如 iptables)中存在过于严格的、未对百度蜘蛛做例外的“默认拒绝”规则所致。
解决方法不是简单地移除所有安全规则,而是需要精细化配置防火墙,确保在保障安全的前提下,允许百度蜘蛛的正常抓取。对于启用 HTTPS 的站点,此问题可能更为凸显,建议站长检查并优化相关防火墙和网络安全组规则。
百度捉取诊断,部分内容捉取失败HTTP/1.1 043 这是返回码不知道因何产生,是否需要处理掉。望回复,在线等。
应该是服务器网络不稳定导致的