想学点人工智能,却被一大堆名词吓坏?想看点直白的说人话的简单介绍,却被各种绕来绕去的语言弄昏头?
没关系,本文就以最简单的语言,为你介绍机器学习中四种主要的学习范式,并通过有趣的例子帮你建立直观的理解。同时,本文也整理了相关的学习资源,帮助你进一步探索。
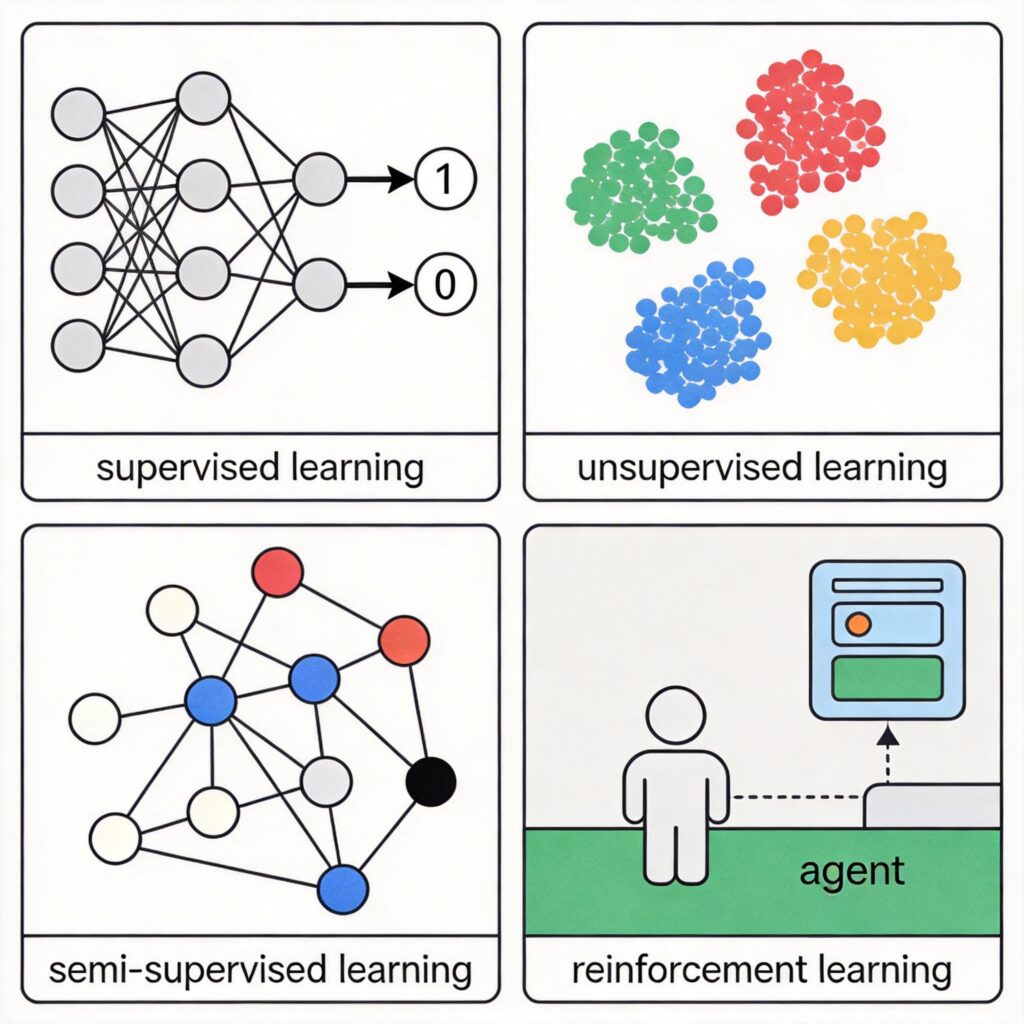
机器学习的四种主要方法
根据训练数据和方法的不同,机器学习主要分为以下四类:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
下文将对每种方法进行直观的解释,并介绍一些常见的术语和对应的学习资源。这种分类方法既适用于传统机器学习,也适用于深度学习。
1. 监督学习
监督学习使用带有明确“正确答案”(标签)的数据来训练模型。例如,如果你想训练一个系统从相册中识别出包含你父母的照片,基本步骤如下:
第一步:数据准备与划分
首先,你需要浏览所有照片,标记出哪些包含你的父母。然后将这些已标记的数据分为两组:
- 训练集:用于训练模型。
- 验证集:用于评估训练后模型的准确率。
从数学角度看,目标是找到一个函数,输入一张照片,输出“是”(1)或“否”(0)。这类问题称为分类。如果输出是连续值(例如预测信用卡还款概率),则称为回归。
第二步:模型训练
训练时,每张图片作为输入,经过神经网络的计算(涉及权重、激活函数等),得到一个预测输出。由于我们已经知道图片的真实标签,因此可以计算预测值与真实值的偏差,这个偏差由成本函数(或称损失函数)衡量。
然后,通过反向传播算法,将误差信息从输出层向输入层传递,并据此调整网络中各神经元的权重和偏差,以最小化成本函数。这个过程通常使用梯度下降等优化方法。
第三步:验证与调优
使用预留的验证集来测试模型的性能。为了获得更好的效果,我们通常需要调整模型的超参数,例如神经网络的层数、神经元数量、学习速率等。训练和验证步骤往往会交叉进行。
第四步:应用
训练好的模型可以集成到应用程序中,例如提供一个 ParentsInPicture(photo) 的 API 接口。当应用调用此 API 时,模型会进行计算并返回结果。
监督学习的挑战在于数据标注成本高昂。因此,它通常应用于标注收益远高于成本的场景,例如医疗影像中癌症的辅助诊断。
2. 无监督学习
无监督学习使用未标记的数据进行训练。系统需要自行发现数据中的内在结构或模式,常见的任务包括聚类和异常检测。
例如,一家服装公司想设计 T 恤的尺码(XS, S, M, L, XL),但不知道每个尺码的具体尺寸范围。他们可以收集大量用户的体型测量数据,然后使用聚类算法(如 K-Means)将用户自然地分成几个群体,每个群体对应一个尺码。
另一个著名案例是 Google Brain 团队的“YouTube 找猫”研究。他们让系统观看海量的 YouTube 视频,在没有给出任何“猫”的标签的情况下,系统通过无监督学习自动将视频内容分类,并成功识别出了“猫”以及其他数千个物体类别。
无监督学习是探索数据内在规律的强大工具。一些重要的无监督学习技术包括:
- 自编码器
- 主成分分析
- K-Means 聚类
- 生成式对抗网络
3. 半监督学习
半监督学习介于监督学习和无监督学习之间。它使用少量已标记数据和大量未标记数据进行训练。这种方法能在显著降低标注成本的同时,达到接近纯监督学习的性能。
直观上,即使不知道数据的精确标签,了解数据本身的分布特征(未标记数据)也能帮助模型更好地划分边界,提高泛化能力。
在实践中,半监督学习能有效扩展模型的分类能力。例如,有研究显示,在某些任务中,每类仅使用30个标记样本的半监督学习,可以达到与每类使用1360个标记样本的监督学习相近的效果,从而让模型能够快速扩展到更多的类别。
4. 强化学习
强化学习让智能体通过与环境互动来学习。它不依赖于带有标签的数据集,而是通过奖励和惩罚信号来指导学习过程。这类似于“冷热游戏”:当你离目标越来越近时,会得到“热”(奖励)的反馈;反之则得到“冷”(惩罚)的反馈。智能体的目标是学习一个策略,以最大化长期累积奖励。
与监督学习即时获得“正确答案”不同,强化学习的反馈通常是延迟且稀疏的。
一个里程碑式的工作是 DeepMind 将深度学习与强化学习结合(深度强化学习),训练出可以玩多种 Atari 游戏的 AI。它在《打砖块》等游戏中表现出色,但在《蒙特祖玛的复仇》这类需要长期规划的游戏上初期表现不佳,原因正是奖励信号过于稀疏。后续研究通过引入自然语言指令(如“爬梯子”、“拿钥匙”)作为额外指导,有效解决了这一问题。
强化学习在游戏、机器人控制、自动驾驶等领域有着广泛的应用前景。
学习资源
以下是一些延伸学习资源,帮助你深入了解这四种机器学习方法:
- 斯坦福大学深度学习教程:涵盖监督与无监督学习,附有代码实例。
网址:http://ufldl.stanford.edu/tutorial/ - 神经网络与反向传播入门:提供直观的解释和演示。
Algobeans 介绍:https://algobeans.com/2016/11/03/artificial-neural-networks-intro2/
Michael Nielsen 著作章节:http://neuralnetworksanddeeplearning.com/chap2.html - 无监督学习课程:Udacity 提供的系统课程。
网址:https://www.udacity.com/course/machine-learning-unsupervised-learning--ud741 - 半监督学习综述:朱晓进教授的详细教程和综述论文。
- 强化学习资料:
DeepMind 深度强化学习介绍:https://deepmind.com/blog/deep-reinforcement-learning/
《Reinforcement Learning: An Introduction》书籍:http://incompleteideas.net/sutton/book/the-book.html