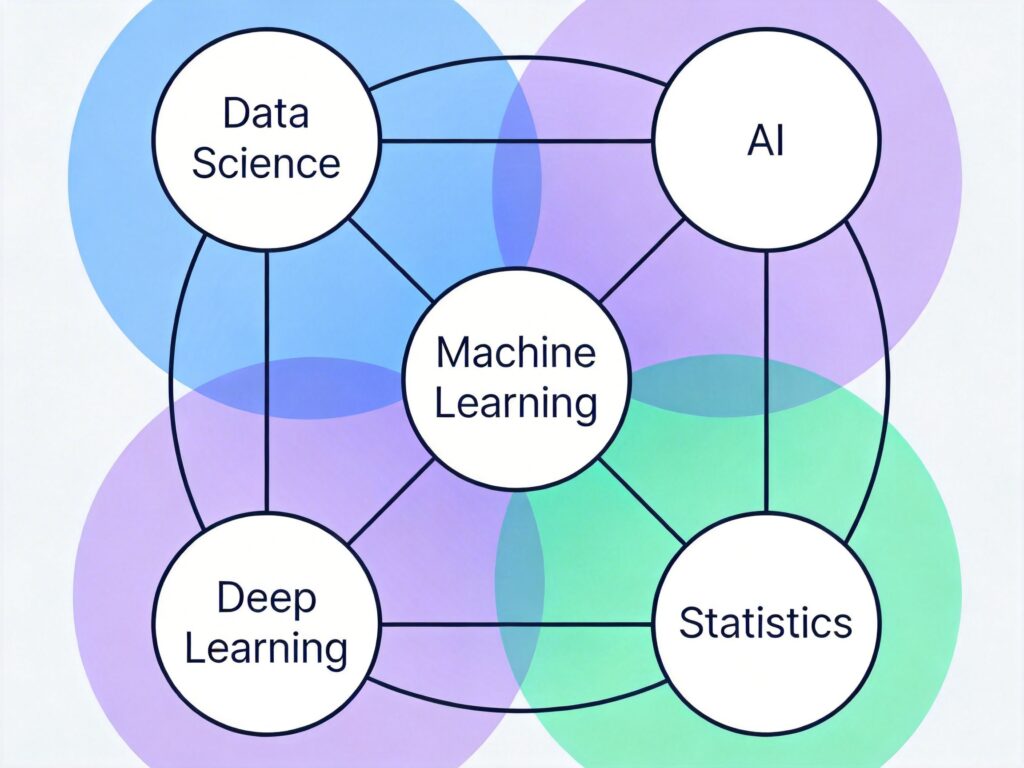
机器学习、数据科学、人工智能、深度学习与统计学的区别与关系
数据科学是一个涵盖广泛的跨学科领域,它与机器学习、深度学习、人工智能、统计学、物联网、运筹学和应用数学等多个领域存在比较和重叠。本文旨在厘清这些关键概念之间的区别与联系,并说明数据科学家在业务环境中的不同角色。
1. 数据科学家的不同类型
数据科学家并非单一角色,根据其技能侧重点和工作性质,可以分为不同类型:
- A型数据科学家(分析师):擅长数据分析、实验设计、预测建模和统计推理。其工作成果不限于学术统计学的“P值和置信区间”,更侧重于业务洞察和决策支持。在业界,他们可能被称为统计学家、定量分析师或决策支持工程师。
- B型数据科学家(建造者):具备与A型相似的背景,但同时是强大的程序员或软件工程师。他们专注于在生产环境中构建和部署数据模型,例如推荐系统、广告投放或搜索引擎算法。
此外,数据科学家的角色还可能涵盖数据工程师、架构师、研究员、业务分析师等多个维度。在初创公司,数据科学家往往需要身兼数职。
数据科学的领域也极为广泛,包括生物信息学、计算金融、流行病学、工业工程、信号处理等。随着物联网(IoT)和机器到机器通信的发展,出现了处理非结构化数据、自动化交易系统的“深度数据科学”,它位于人工智能、物联网和数据科学的交叉点。
2. 机器学习与深度学习的区别
机器学习(Machine Learning)是一类算法的总称,这些算法通过从数据(训练集)中学习,自动调整参数,以做出预测或优化系统。常见技术包括:
- 监督学习(如分类、回归):逻辑回归、决策树、支持向量机、朴素贝叶斯。
- 无监督学习(如聚类、降维):K-means、主成分分析(PCA)。
- 集成方法:随机森林、梯度提升。
深度学习(Deep Learning)是机器学习的一个子集,特指使用深层神经网络(包含多个隐藏层)的模型。它在计算机视觉、自然语言处理等领域取得了突破性进展。深度学习模型能够自动学习数据的层次化特征表示。
人工智能(Artificial Intelligence)是一个更宏观的领域,旨在让机器执行通常需要人类智能的任务(如规划、视觉识别、语言翻译)。机器学习是实现AI的一种主要方法。当机器学习算法(特别是深度学习)被用于自动化复杂任务(如自动驾驶)时,通常被视为AI的应用。
3. 机器学习与统计学的区别
统计学和机器学习都涉及从数据中学习,但侧重点不同:
- 统计学:更侧重于基于概率理论的推断、估计和假设检验,强调模型的可解释性、置信区间和p值。传统统计学通常处理结构化、规模较小的数据。
- 机器学习:更侧重于预测的准确性和算法的泛化能力,常用于处理大规模、高维数据(如图像、文本)。许多机器学习模型(如深度学习)被视为“黑箱”,可解释性较弱。
两者界限正在模糊,现代统计学也吸收了机器学习的思想(如正则化、交叉验证),而机器学习也借鉴了统计推断理论。
4. 数据科学与机器学习的区别
数据科学的范围比机器学习更广泛。机器学习(和统计学)是数据科学工具箱中的重要组成部分,但数据科学涵盖整个数据生命周期:
- 数据获取与集成:从各种来源收集、清洗、整合数据。
- 数据存储与工程:设计分布式架构、数据管道。
- 探索性数据分析与可视化:使用图表、仪表板理解数据。
- 建模与分析:应用统计方法和机器学习算法。
- 部署与运维:将模型投入生产环境,实现自动化决策。
- 商业智能与决策支持:将分析结果转化为业务行动。
简言之,数据科学是一个端到端的流程,而机器学习是该流程中实现自动建模和预测的核心技术环节。数据可能来自机器(传感器日志)或非机器来源(手动调查),且并非所有数据科学活动都涉及“学习”。
总结关系
这些领域的关系可以概括为:
- 人工智能(AI) 是最广泛的概念,旨在创造智能机器。
- 机器学习(ML) 是实现AI的主要途径,让机器从数据中学习。
- 深度学习(DL) 是机器学习的一个分支,基于深层神经网络。
- 数据科学(DS) 是一个跨学科领域,利用ML、DL、统计学等方法,从数据中提取洞察并驱动决策。
- 统计学 为数据科学和机器学习提供理论基础和推断工具。
在实际工作中,这些领域高度交叉融合。选择何种技术取决于具体问题、数据特性和业务目标。